New ELF Builder

LIEF’s Modification Process
Let’s start with a small recap of the LIEF modification process.
To enable executable file formats modification, LIEF transforms the raw executable formats into an object representation. This object can be manipulated with an API that is mainly exposed through the following interfaces:
| C++ | Python |
|---|---|
| LIEF::ELF::Binary | lief.ELF.Binary |
| LIEF::PE::Binary | lief.PE.Binary |
| LIEF::MachO::Binary | lief.MachO.Binary |
Then, the LIEF’s builders take the object representation and (try to) reconstruct an executable according to the user’s changes.
Challenges in Modifying ELF Binaries
Compared to the PE and Mach-O formats, the ELF format is far the more trickier to handle for both: parsing and modifying. First off, there is a strong relationship between the segment’s virtual address and the file’s offset associated with its content. This relationship is ruled by the following property:
$$\text{\textcolor{red}{file\_offset}} \equiv \text{\textcolor{blue}{virtual\_address}} \mod{\textcolor{green}{\text{page\_size}}}$$So basically, we can’t insert a segment at an arbitrary virtual address.
The second difficulty is about the strings table optimization that is performed on the .dynstr section.
To understand how this optimization works, let’s consider these two functions:
1int foo() {
2 return 1;
3}
4
5int call_foo() {
6 return foo();
7}
When these functions are compiled, the compiler generates two symbols for which the names of the symbols are referenced
by the field st_name. Usually, this field points in the .dynstr section:
1struct Elf_Sym {
2 Elf_Word st_name; // Offset of the symbol's name in the .dynstr section
3 ...
4};
Naively, we could imagine that the .dynstr section contains these two symbols names, one next to the other:
00000130 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000140 0d 00 00 00 12 00 01 00 00 00 00 00 00 00 00 00 |................|
00000150 0b 00 00 00 00 00 00 00 0a 00 00 00 12 00 01 00 |................|
00000160 0b 00 00 00 00 00 00 00 0b 00 00 00 00 00 00 00 |................|
00000170 00 74 6f 74 6f 2e 63 70 70 00 66 6f 6f 00 64 6f |.test.cpp.foo.do|
00000180 5f 66 6f 6f 00 00 00 00 10 00 00 00 00 00 00 00 |_foo............|
00000
With such a layout, Elf_Sym("foo").st_name would point to the offset 0x17A while
Elf_Sym("do_foo").st_name would point to the offset 0x17E.
But the real layout of the .dynstr is a bit smaller:
00000130 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000140 0d 00 00 00 12 00 01 00 00 00 00 00 00 00 00 00 |................|
00000150 0b 00 00 00 00 00 00 00 0a 00 00 00 12 00 01 00 |................|
00000160 0b 00 00 00 00 00 00 00 0b 00 00 00 00 00 00 00 |................|
00000170 00 74 6f 74 6f 2e 63 70 70 00 64 6f 5f 66 6f 6f |.test.cpp.do_foo|
00000180 00 00 00 00 00 00 00 00 10 00 00 00 00 00 00 00 |................|
00000190 04 00 00 00 03 00 00 00 fc ff ff ff ff ff ff ff |................|
As we can see, it only contains the do_foo string. Since foo is a suffix of do_foo,
st_name can point to a different offset of the same string. In this layout Elf_Sym("foo").st_name points
to the offset 0x17C and Elf_Sym("foo").st_name points to 0x17A.
Consequently, instead of taking the space of len(call_foo) + 1 + len(foo) + 1, it only takes len(call_foo) + 1
The consequence of this optimization is that we can’t naively push back the symbols names in the .dynstr section.
Instead, we have to sort the symbols names such as this optimization can take place.
In addition to this strings optimization, ELF object files (.o) generated by Clang share the same section for
the names of the sections and for the symbols’ names.
1$ readelf -hWS ./hello.o
2
3ELF Header:
4 Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
5 [...]
6 Number of section headers: 11
7 Section header string table index: 1
8
9Section Headers:
10 [Nr] Name Type Address Off Size ES Flg Lk Inf Al
11 [ 0] NULL 0000000000000000 000000 000000 00 0 0 0
12 [ 1] .strtab STRTAB 0000000000000000 000199 000078 00 0 0 1
13 [..]
14 [10] .symtab SYMTAB 0000000000000000 0000c0 000090 18 1 4 8
As we can notice, the Section header string table index of the ELF header indexes the .strtab
which is also the section associated with the symbols’ names (cf. the link attribute of the .symtab).
It results that we have to consider this kind of ELF file differently from regular libraries or executables.
There are other nasty tricks like the management of the ELF constructors between Linux and Android but this will be covered in another blog post.
The New ELF Builder
For the historical context, I created LIEF during my internship at Quarkslab with the supervision of Serge-Sans-Paille and Adrien Guinet and the trust/boost from Fred Raynal.
Even though I had the chance to get valuable feedback and review from them, I clearly made poor design decisions in LIEF and the implementation of the ELF builder is one of them.
Basically, the implementation is recursive such as in the extreme cases the builder re-computes the same information several times.
In the new implementation, we added a new stage in the build process that pre-computes the offsets of the new sections and the data that need to be relocated. This pre-computation enables to know exactly which parts of the ELF structures need to be relocated according to the user’s changes. This computation is managed by the Layout class which has two implementations depending on whether it is an ELF object or a library/executable.
Compared to the previous ELF builder, this new implementation produces smaller files (with fewer ELF segments) as exposed in the following figure. This figure compares the number of segments between the former and the new implementation:
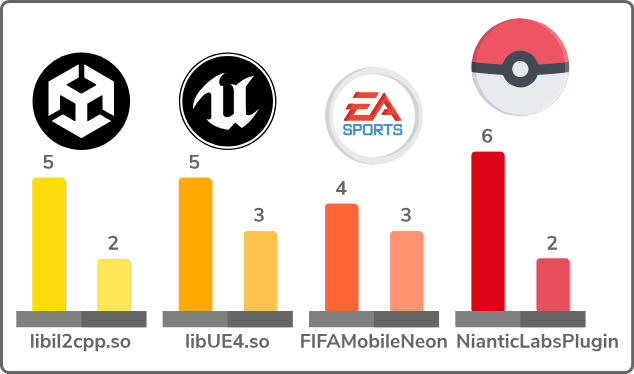
In addition, it supports larger binaries faster as a consequence of the new linear implementation of the ELF builder :)
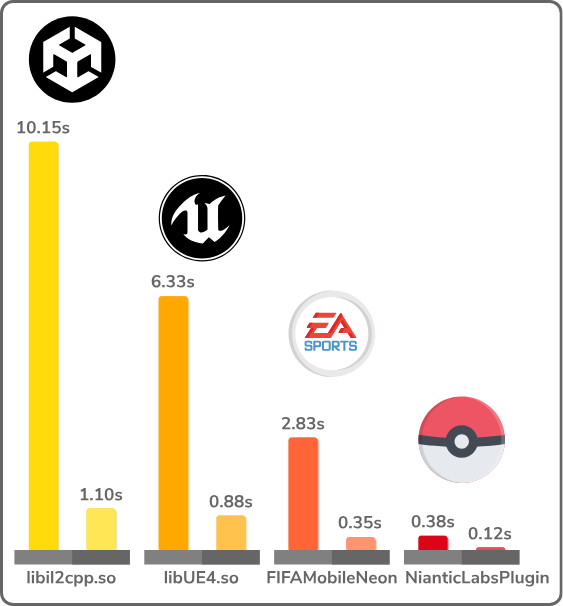
To perform these benchmarks, we generated ELF binaries with the modifications described in the following script:
1import lief
2
3elf: lief.ELF.Binary = lief.parse(file_path.as_posix())
4
5# Force relocating the .dynamic/.dynstr
6elf.add_library("a_very_long_name.so")
7
8# For relocating the interpreter
9elf.interpreter = "/a/very/longlonglong/interpreter-1.2.3.bin"
10
11# Force relocating .dynsym / .gnu.hash table
12for i in range(10):
13 elf.add_exported_function(0xdeadc0de + i, f"new_export_{i}")
14
15# Add a segment
16segment = lief.ELF.Segment()
17segment.type = lief.ELF.SEGMENT_TYPES.LOAD
18segment.content = [0xcc] * 0x23
19
20elf.add(segment)
21
22elf.write("/tmp/bench.bin")
The raw results of the benchmark are also available here
Final Words
These new improvements introduce breaking changes in the ELF binaries generated by LIEF but:
- The final binary size should be smaller
- The building time should be much faster
We tried to cover most of the cases in the tests suite but some corner cases with exotic compilers or linkers might break the final binaries.
Since this improvement aims at being in the next release, feel free to drop an email or to open an issue if you find a bug with this new implementation.
Since September I continue maintaining LIEF exclusively in my spare so issues and new features are addressed with more delay.